Определение атрибутных грамматик
Атрибутной грамматикой называется четверка AG = (G, AS, AI, R), где


Атрибутная грамматика AG сопоставляет каждому символу X из N

атрибутов всех символов из N
Пусть правило p из P имеет вид X0

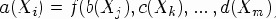
где 0


Таким образом, семантическое правило определяет значение атрибута a символа Xi
на основе значений атрибутов b, c, ..., d символов Xj, Xk, ..., Xm
соответственно.
В частном случае длина n правой части правила может быть равна нулю, тогда будем говорить, что атрибут a символа Xi
«получает в качестве значения константу».
В дальнейшем
будем считать, что атрибутная грамматика не содержит семантических правил для вычисления атрибутов терминальных символов. Предполагается, что атрибуты терминальных символов - либо предопределенные константы, либо доступны как результат работы лексического анализатора.
Пример 5.5. Рассмотрим атрибутную грамматику, позволяющую вычислить значение вещественного числа, представленного в десятичной записи. Здесь N = {Num, Int, Frac}, T = {digit, .}, S = Num, а правила вывода и семантические правила определяются следующим образом (верхние
индексы используются для ссылки на разные вхождения одного и того же нетерминала):
Num  | v(Num) = v(Int) + v(Frac) |
| p(Frac) = 1 | |
| Int | v(Int) = 0 |
| p(Int) = 0 | |
| Int1 | v(Int1) = v(digit) * 10p(Int2) + v(Int2) |
| p(Int1) = p(Int2) + 1 | |
| Frac | v(Frac) = 0 |
| Frac1 | v(Frac1) = v(digit) * 10-p(Frac1) + v(Frac2) |
| p(Frac2) = p(Frac1) + 1 | |
Для этой грамматики
| AS(Num) = {v}, | AI(Num) = |
| AS(Int) = {v, p}, | AI(Int) = |
| AS(Frac) = {v}, | AI(Frac) = {p}. |
разбора T этой цепочки в грамматике G. Каждый внутренний узел этого дерева помечается нетерминалом X0, соответствующим применению p-го правила грамматики; таким образом, у этого узла будет n непосредственных потомков (рис. 5.2).
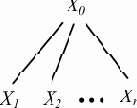
|
значения vj, vk, ..., vm
соответственно, а v = f(v1, v2, ..., vm). Процесс вычисления атрибутов на дереве продолжается до тех пор, пока нельзя будет вычислить больше ни одного атрибута. Вычисленные в результате атрибуты корня дерева представляют собой «значение», соответствующее данному дереву вывода.
Заметим, что значение синтезируемого атрибута символа в узле синтаксического дерева вычисляется по атрибутам
символов в потомках этого узла; значение наследуемого атрибута вычисляется по атрибутам «родителя' и «соседей».
Атрибуты, сопоставленные вхождениям символов в дерево разбора, будем называть вхождениями атрибутов в дерево разбора, а дерево с сопоставленными каждой вершине атрибутами - атрибутированным деревом разбора.
Пример 5.6. Атрибутированное дерево для грамматики из предыдущего примера и цепочки w = 12.34 показано на рис. 5.3.
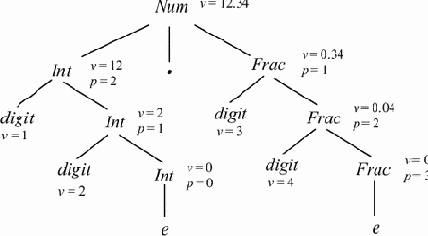
|
Между вхождениями атрибутов в дерево разбора существуют зависимости, определяемые семантическими правилами, соответствующими примененным синтаксическим правилам. Эти зависимости могут быть представлены в виде ориентированного графа следующим образом.
Пусть T - дерево разбора. Сопоставим
этому дереву ориентированный граф D(T), узлами которого являются пары (n, a), где n - узел дерева T, a - атрибут символа, служащего меткой узла n. Граф содержит дугу из (n1, a1) в (n2, a2) тогда и только тогда, когда семантическое правило, вычисляющее атрибут a2, непосредственно использует значение атрибута a1. Таким образом, узлами графа D(T) являются атрибуты, которые нужно вычислить, а дуги определяют зависимости, подразумевающие, какие атрибуты вычисляются раньше,
а какие позже.
Пример 5.7. Граф зависимостей атрибутов для дерева разбора из предыдущего примера показан на рис. 5.4.
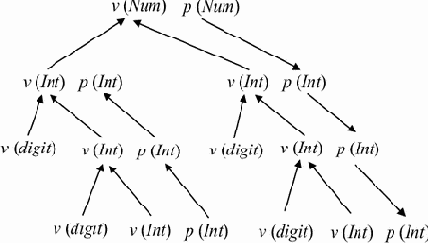
|
