Обменная сортировка
Обменная сортировка некоторым систематическим образом меняет местами пары имен, не отвечающие порядку, до тех пор, пока такие пары существуют. Фактически алгоритм 14.1 можно рассматривать как обменную сортировку, в которой имя

Пузырьковая сортировка. Наиболее очевидный метод систематического обмена местами имен с неправильным порядком состоит в просмотре пар смежных имен последовательно слева направо и перемене мест тех имен, которые не отвечают порядку.
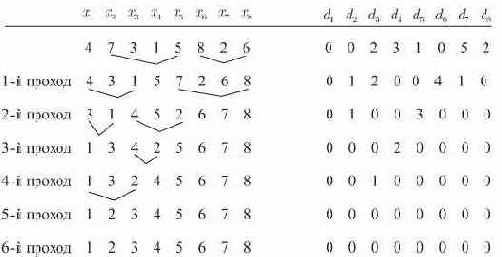
Рис. 14.2. Пузырьковая сортировка, примененная к таблице. Показан вектор инверсии таблицы после каждого прохода
Эта техника получила название пузырьковой сортировки, так как большие имена "пузырьками всплывают" вверх (то есть на правый конец) таблицы. В алгоритме 14.2 эта простая идея реализуется с одним небольшим усовершенствованием: ясно, что не имеет смысла продолжать просмотр для больших имен (в правом конце таблицы), про которые известно, что они находятся на своих окончательных позициях. В алгоритме 14.2 используется переменная


равно наибольшему индексу



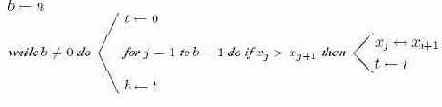
Алгоритм 14.2. Пузырьковая сортировка
Анализ пузырьковой сортировки зависит от трех факторов: числа проходов (то есть числа выполнений тела цикла




дает возможность предположить, что каждый проход пузырьковой сортировки, исключая последний, уменьшает на единицу каждый ненулевой элемент вектора инверсий и циклически сдвигает вектор на одну позицию влево; легко доказать, что это верно в общем случае, и поэтому число проходов равно единице плюс наибольший элемент вектора инверсий. В лучшем случае имеется всего один проход, в худшем случае -








Пузырьковую сортировку можно несколько улучшить, но при этом она все еще не сможет конкурировать с более эффективными алгоритмами сортировки. Ее единственным преимуществом является простота.
Как в простой сортировке вставками, так и в пузырьковой сортировке (алгоритм 14.2) основной причиной неэффективности является тот факт, что обмены дают слишком малый эффект, так как в каждый момент времени имена сдвигаются только на одну позицию. Такие алгоритмы непременно требуют порядка

операций, как в среднем, так и в худшем случаях.
Быстрая сортировка. Идея метода быстрой сортировки состоит в том, чтобы выбрать одно из имен в таблице и использовать его для разделения таблицы на две подтаблицы, составленные соответственно из имен меньших и больших выбранного, которые затем рекурсивно сортируются с использованием быстрой сортировки. Разделение можно реализовать, одновременно просматривая таблицу и слева направо, и справа налево, меняя местами имена в неправильных частях таблицы. Имя, используемое для расщепления таблицы, затем помещается между двумя подтаблицами, и две подтаблицы сортируются рекурсивно.
В алгоритме 14.3 показаны детали быстрой сортировки для сортировки таблицы

используется для разбиения таблицы на подтаблицы. На рис. 14.3 показано, как алгоритм 14.3 использует два указателя



встречаются, то есть когда





Алгоритм 14.3. Рекурсивный вариант быстрой сортировки, использующий первое имя для расщепления таблицы. Предполагается, что имя
определено и больше или равно

Рис. 14.3. Фаза разбиения быстрой сортировки, использующей первое имя для разбиения таблицы. Значение
Алгоритм 14.3 изящен, но непрактичен. Проблема состоит в том, что рекурсия используется для записи подтаблиц, которые рассматриваются на более поздних этапах, и в худших случаях (когда таблица уже отсортирована) глубина рекурсии может равняться




увеличить изображение
Алгоритм 14.4.Итерационный вариант быстрой сортировки

