Оптимальные деревья бинарного поиска
Бинарный поиск в последовательно распределенной таблице ( алгоритм 13.4.) обеспечивает очень быстрое нахождение имен, которые являются средними точками на раннем этапе процесса деления пополам, именно имен, близких к вершине дерева


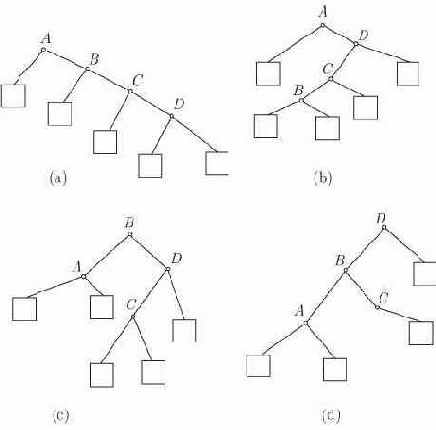
Рис. 13.1. Четыре дерева бинарного поиска над множеством имен {A,B,C,D}
На практике в большинстве таблиц встречаются имена, к которым обращаются гораздо чаще, чем к другим, и "привилегированные" места в таблице разумно постараться использовать для наиболее часто вызываемых имен, а не для имен, выбранных для этих мест в результате бинарного поиска. Это невозможно осуществить для последовательно распределенных таблиц, поскольку место имени определяется его положением относительно естественного порядка имен в таблице. Введем структуру данных, легко приспосабливаемую как к месту бинарного поиска, так и к возможности выделять точки, в которых таблица делится на две части.
Деревом бинарного поиска над именами

называется расширенное бинарное дерево, все внутренние узлы которого помечены различными именами из списка


Поиск имени

- Если корня нет (дерево пусто), то в таблице отсутствует и поиск завершается безуспешно.
- Если совпадает с именем в корне, поиск завершается успешно.
- Если предшествует имени в корне, поиск продолжается ниже в левом поддереве корня.
- Если следует за именем в корне, поиск продолжается ниже в правом поддереве корня.
Пусть бинарное дерево имеет вид, в котором каждый узел представляет собой тройку (LEFT, NAME, RIGHT), где LEFT и RIGHTсодержат указатели левого и правого сыновей соответственно, и NAME содержит имя, хранящееся в узле.
Указатели могут иметь значение

Эта процедура нахождения имени

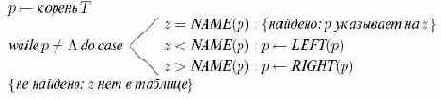
Алгоритм 13.5. Поиск в дереве бинарного поиска
